从输入URL开始构建浏览器知识体系
从浏览器输入 URL 到页面呈现都发生了什么
- 输入 URL
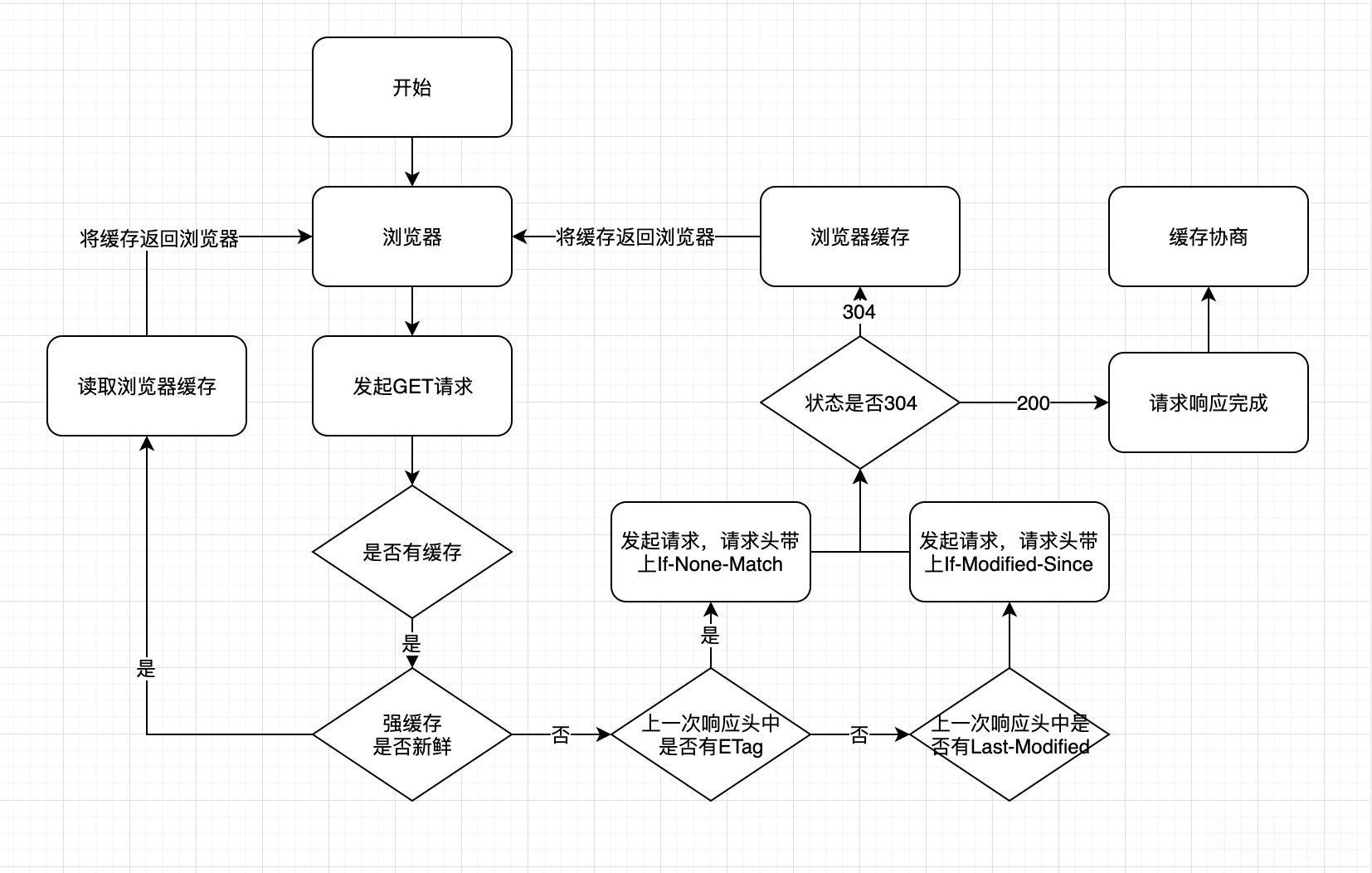
- 查找缓存,有缓存读取缓存,没有进行下一步
- DNS 域名解析,解析出域名对应的 IP 地址
- 和服务器建立 TCP 连接
- 发送 HTTP 请求
- 服务端响应请求,返回结果
- 断开 TCP 连接
- 浏览器渲染
缓存
- 首先查找浏览器缓存
- 然后查找操作系统缓存
- 查找路由器缓存
- 查找 ISP 缓存
http 缓存
强缓存
如果命中强缓存就无需向服务器发送请求。
在 http1.0 通过 Expires 来判断是否命中强缓存,这个字段代表资源过期时间,如果资源未过期,即可读取缓存,但是由于浏览器时间和服务器时间可能存在差异,导致缓存失效。
在 http1.1 通过 Cache-Control 进行判断,和 Expires 不同的是,Cache-Control 的 max-age 字段代表的是缓存的时长,在这个时长内缓存都是有效的,这样就能避免由于时间误差导致缓存失效。
协商缓存
当强缓存失效就进入到了协商缓存,协商缓存需要向服务器发送请求。协商缓存通过 Last-Modified 和 ETag 来判断。
Last-Modified 即最后修改时间,在浏览器接收到请求,会在请求头保存最后修改时间在 If-Modified-Since 字段,当该字段和服务器的最后修改时间一致,标识服务端资源没有再被更改,命中协商缓存。
ETag 和 Last-Modified 的区别在于,后者按照修改时间界定资源是否更新,而 ETag 则是通过资源生成的唯一 hash 值来进行界定,只要资源发生改变就会生成新的 hash 值,通过这个值就能判断是否命中协商缓存。
TCP 和 UDP
TCP
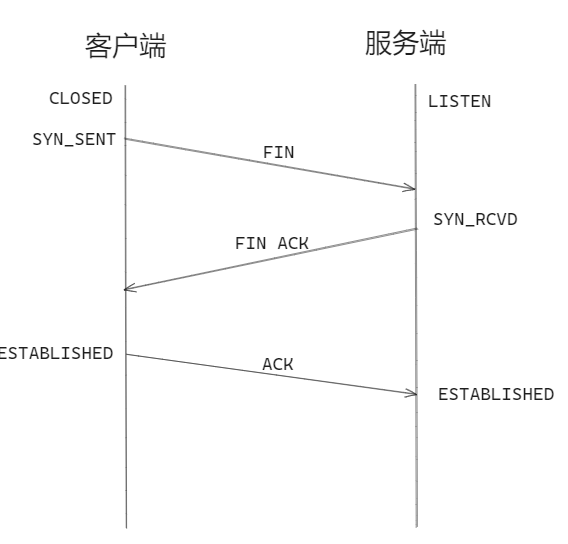
三次握手
三次握手主要目的是确认客户端和服务端的发送和接收功能是否正常。
第一次握手;客户端向服务端发送 SYN 标记的包,告诉服务端请求建立连接(确认客户端发送功能正常)
第二次握手:服务端接收到 SYN 包并确认,发送包 SYN、ACK 到客户端响应连接(确认服务端发送和相应功能正常)
第三次握手:客户端接收到服务端响应,发送确认包 ACK 到服务端,连接建立成功(确认客户端接收功能正常)
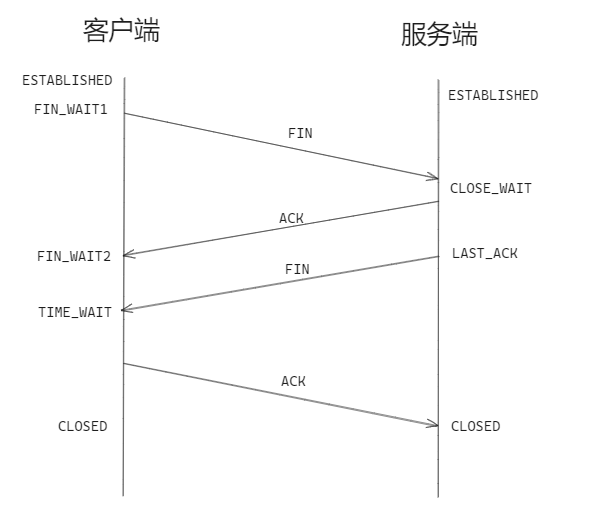
四次挥手
第一次挥手:客户端发送 FIN 包请求关闭连接,客户端此时不再发送数据,变成 FIN_WAIT 状态
第二次挥手:服务端接收到 FIN 包,释放 TCP 连接,发送确认包 ACK,进入 CLOSE_WAIT 状态,此时客户端到服务端的连接已经关闭
第三次挥手:等到服务端数据发送完要断开连接,发送 FIN 包给客户端请求断开连接,此时服务端处于 LAST_ACK 状态
第四次挥手:客户端收到服务端请求断开 FIN 包,发送 ACK 应答包,此时客户端进入 TIME_WAIT 状态,等待2MSL(报文最大生存时间)服务端收到 ACK 包,进入 CLOSED 状态
TCP 如何保证数据包传输有序可靠
- 序列号和确认应答:每个 TCP 数据包都包含一个序列号,接收方在收到数据包后会发送一个确认应答,确认已成功接收到数据。
- 超时重发:如果发送方在一定时间内没有收到接收方的确认应答,就会重新发送相同的数据包,直到收到应答或重传次数超过规定的最大次数为止。
UDP
- 缺点
由于 UDP 协议是面向无连接的,不需要像 TCP 一样需要三次握手才能建立连接,UDP 想发送就发送,而且 UDP 始终以恒定的速度发送数据,在网络出现波动的情况下,可能出现丢包的情况,就算丢包了,UDP 也不会重发,它根本不关心数据是否发送成功,所以 UDP 是不可靠的。 - 优点
UDP 的头部开销只有八个字节,比 TCP 少得多,UDP 还支持一对多,多对多的传输方式
HTTP
HTTP 全称超文本传输协议(Hypertext Transfer Protocol)
各个版本特点
HTTP1.0
- 默认使用短连接
- 使用 If-Modified-Since,Expires来做缓存判断的标准
- 存在带宽浪费现象,客户端只需要某个对象一部分,服务器也会把整个对象传过来
HTTP1.1
- 支持长连接
- 引入 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 控制缓存
- 优化带宽浪费,允许只请求资源某部分
- 新增错误状态码(24个)
HTTP2.0
- 引入多路复用,即可以只通过一个 TCP 连接就可以传输所有的请求数据
- 二进制传输,HTTP1 是基于文本,HTTP2.0 采用二进制
- 头部压缩,在 HTTP1 中 header 带有大量信息,每次都重新发送,HTTP2.0 通过 encoder 减少 header 大小,并且在两端维护索引表记录出现过的 header,再次传输只需要传输键名就能拿到值。
- 支持服务端 push
HTTP3.0
- 在 HTTP2.0 下使用了多路复用,只使用一个 TCP 连接,当出现丢包的时候,整个 TCP 等待重传,造成堵塞。所以 HTTP3.0 使用基于 UDP 的 QUIC 协议
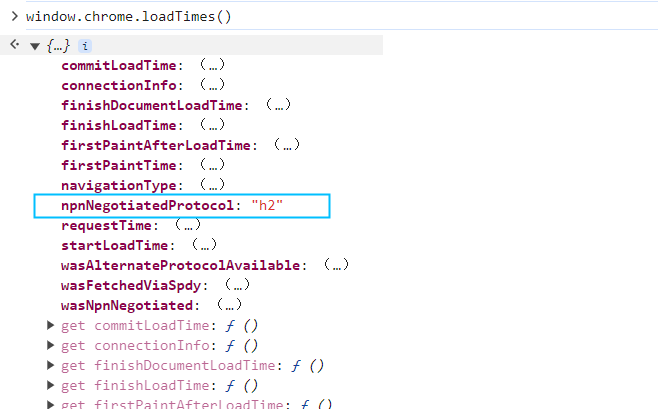
判断使用的哪个版本
在控制台输入 window.chrome.loadTimes()
网络模型
- 应用层:最高层的网络协议,提供应用程序与网络之间的接口,支持各种应用程序(如Web浏览器、电子邮件等)进行通信。
- 运输层:负责提供端到端的数据传输服务,确保数据可靠地传输,常用的传输协议有TCP(传输控制协议)和UDP(用户数据报协议)。
- 网络层:负责通过路由选择算法将数据包从源主机传输到目标主机,实现数据的网络互联与路由选择。
- 数据链路层:负责将原始的比特流进行分组并转换为数据帧,处理数据帧之间的错误校验和流量控制,以确保数据的可靠传输。
- 物理层:负责传输数据,将帧中的一个个比特从一个节点传输到另外的节点
OSI模型
- 应用层
- 表示层
- 会话层
- 运输层
- 网络层
- 链路层
- 物理层
浏览器渲染
浏览器渲染过程
- 解析 HTML、CSS 生成 DOM 树、CSSOM 树,
- DOM + CSSOM 生成 Render Tree
- 根据生成的 Render Tree 进行回流,得到节点几何信息
- 根据 Render Tree 和 回流得到节点绝对像素
- 将像素发送给 GPU 在页面显示
HTML文档解析时间线
- 浏览器生成 document 对象
- 解析文档(从 html 第一行开始)、构建DOM树
document.readyState = ‘loading’ 加载中阶段 - link 开新的线程 -> 异步加载 css 外部文件 style
- 没有设置异步加载的 script ,阻塞文档解析,等 js 脚本执行完,继续解析文档
- 有异步加载的 script ,异步加载js脚本,不阻塞解析文档 (异步加载文档不能使用document.write,会报错)
- 解析文档遇到 img 先解析这个节点,创建加载线程 异步加载图片资源 不阻塞文档解析
- 文档解析完成
document.readState = ‘interactive’ 解析完成 交互阶段 - 文档解析完成 defer script js脚本开始按照顺序执行
- 文档解析完成:立即触发 DOMContentLoaded 事件,程序由 同步脚本执行阶段 走向 事件驱动阶段,此时用户可以进行操作
- async script 加载完并执行,img 等资源加载完成 window.onload 事件触发
document.readState = ‘complete’ 文档加载完毕阶段
重绘&重排
- 重绘:重绘指的是浏览器根据元素样式的更改重新绘制页面的过程,但并不影响页面中元素的布局
- 重排:重排指的是浏览器重新计算文档流中元素的位置和大小,然后根据新的布局信息进行重新排列的过程
如何触发
- 添加、删除、更新DOM节点
- 通过display: none隐藏一个DOM节点-触发重排和重绘
- 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的DOM节点添加动画
- 用户行为,例如调整窗口大小,改变字号,或者滚动
如何避免
- 合并样式修改:尽量避免对页面中的元素频繁进行样式更改。可以将多个样式更改合并成一次操作,或者使用类似于requestAnimationFrame的方法来批量处理样式
- 使用文档片段:使用文档片段(DocumentFragment)进行离线操作,然后一次性将其添加到文档中,减少对实际 DOM 树的操作。
- 不要把 DOM 结点的属性值放在循环里当成循环里的变量。
- 动画开始GPU加速,translate使用3D变化