无法避免的正则表达式
前言
什么是正则表达式?
我们在日常开发中总是能遇到一些需要校验的功能,例如校验邮箱、手机号等等,或者对一些字符串做替换处理等,正则表达式总是避不开的。个人理解正则就是用来匹配字符,校验字符规则,或者是提取一段字符中的内容。本文只介绍正则的一些基本使用。
匹配字符
匹配模糊长度
1 | |
通过 {m,n} 的形式来设置匹配的长度范围,以上代码匹配的就是 b 出现 1 - 5 次。而且 {m,n}中,可以省略,代表匹配出现至少 m 次,或者只写 m,{m} 代表匹配只出现 m 次。
匹配模糊字符
1 | |
通过 [] 的形式来设置可能出现的字符,以上代码匹配的就是 bcde 中出现任意一个。
排除某些字符用 ^
1 | |
通过 ^ 来设置不匹配哪些字符,以上代码匹配的就是 除了 bcde 字符外任意字符
多分支匹配
1 | |
多分支匹配通过 | 实现,意思是匹配其中任意一个即可,和 JS 中的 或 类似,另外需要注意当前面的分支匹配上后就不会继续进行匹配了。
匹配位置
锚字符
- ^ 匹配开头
- $ 匹配结尾
- \b 单词字符和非单词字符之间,也就是 \w 和 \W 之间
- \B 把 \b 取反
- (?=p) p 前的位置
- (?=p) 除了p 前的位置
开头结尾 ^ $
1 | |
以上代码就是匹配以 a 开头,b 结尾的字符串,另外字符串有一个方法 replace 可以通过匹配位置进行替换。
1 | |
通过匹配字符串的开头和结尾位置,替换成 #。
1 | |
需要注意的是,在多行模式匹配下,开头和结尾是每行的开头结尾。
单词边界 \b \B
1 | |
单词边界就是 \w 和 \W 之间,也就是所有数字、字符串以及下划线 和 其他字符之间,也就是下图箭头所指的位置。注意看箭头两边的字符分别是\w 和 \W,另外要注意的是开头和结尾也是 \W。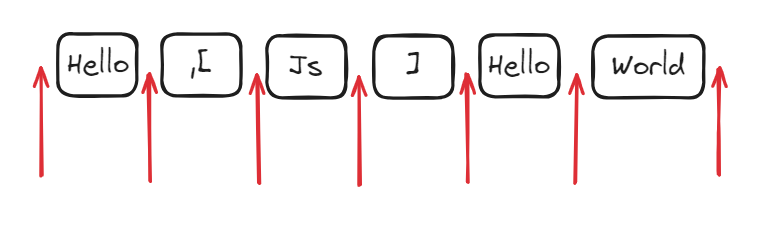
那 \B 就很好理解了,就是除了 \w 所指位置的其他位置。
先行断言
(?=p)(正向先行断言)指 p 前面的位置,这个 p 就是一个子模式,先用 p 进行匹配,然后再取他前面的位置
1 | |
(?!p)(负向先行断言)就是和 (?=p) 相反,就是先匹配非 p 然后取前面的位置
1 | |
(?<=p) 指 p 后面的位置
1 | |
(?>!p) 和 (?<=p) 相反
1 | |
实践
给金额加上千分位逗号 例如 123456789 -> 123,456,789
解题思路:先选中倒数第三位前的位置替换成逗号,然后出现多次,最后排除开头的位置。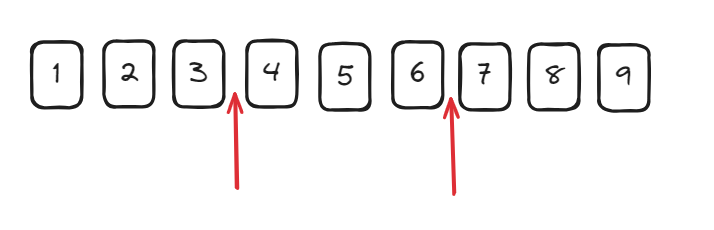
我们要做的就是选中图中箭头的位置
第一步
1 | |
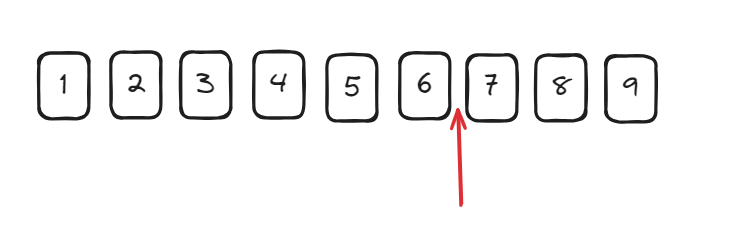
上面的正则匹配的就是以三个数字结尾前的位置,然后替换成逗号。
第二步
1 | |
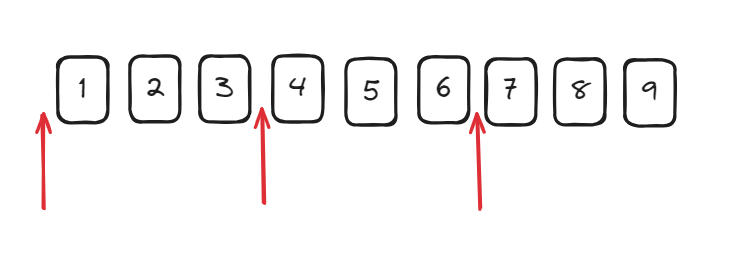
通过 + 让三个数字匹配多次,达到匹配上每三位数字前的位置,然后替换成逗号,这时发现开头的位置多了一个逗号,我们需要排除掉开始的位置
第三步
1 | |
通过(?!^)匹配除了开始位置的其他位置,这种方法就排除掉了开头,达到了预期的效果。
影响量词的匹配行为
贪婪匹配
正则在进行量词匹配时,会尽可能地多匹配。
1 | |
惰性匹配(非贪婪匹配)
我们使用 ? 来声明惰性匹配,惰性匹配每次只满足最低要求即可。
1 | |
分组
我们可以通过()来对正则表达式进行分组,如
1 | |
把 abc 括起来使他们成为一个分组,+的就是这个分组。
提取分组的数据
我们对正则进行分组匹配后还可以拿到分组匹配到的数据,
1 | |
两个输出结果相同,输出结果: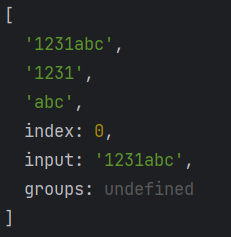
需要注意的是,在捕获分组的时候,使用全部匹配 /g 就不返回分组信息了。
1 | |
反向引用
在正则表达式中,如果有一个不确定的字符,后面还需要用到这个相同的字符,就可以用反向引用的方式
1 | |
这里我们用 \1 来引用第一个分组的字符,所以当前面是 , 后面也只能是 ,,这样就能做到前后一致。
另外如果出现嵌套括号的情况,我们以左括号出现的顺序为引用的顺序
1 | |

如果不希望分组被提取引用,使用非捕获分组 (?:p),我们把上面的代码修改一下看结果。
1 | |
输出结果:
附录
详细查阅: 正则表达式
匹配数量简写
- {m,} 至少出现 m 次数
- {m} 只出现 m 次数
- ? 不出现或者出现一次 等价于 {0,1}
- + 至少出现一次
- * 有没有都行
匹配范围简写
- \d 表示数字
- \D 除了数字外任意字符
- \w 数字+字母+下划线
- \W 除了 \w
- \s 空白字符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符
- \S 非空白符
- . 任意字符
修饰符
- i 不区分大小写
- g 全局匹配
- m 多行匹配
- s 允许 . 匹配换行符。
- u 使用 unicode 码的模式进行匹配。
- y 粘性 匹配从目标字符串的当前位置开始。